Índice
Introdução
Esse artigo vai te ensinar a criar uma planilha no google sheets usando a linguagem python com as libs gspread e a lib oficial do google google-api-python-client.
Vamos usar o CSV gerado no post Selenium com Python para criar uma planilha no Google Drive.
Para isso, será necessário criar um projeto no google cloud, configurar o acesso a API do Google Sheets e configurar uma credencial de acesso para o nosso programa, que será feito em python.
Criando um App no Google
O primeiro passo é criar um Projeto no Google Cloud clicando aqui. Para criar um projeto, no canto superior esquerdo, clique em ≡ → IAM & Admin → Create a Project, como mostra a figura:
Dê um nome para seu projeto e aperte em Create:
Em seguida, precisamos configurar o nosso projeto para permitir que ele acesse a API do Google Sheets. Para isso acesso o menu ≡ → API & Services → Library
No campo de pesquisa, digite "sheets" e aperte "enter" para pesquisar a API que queremos.
Selecione a API "Google Sheets API”:
Aperte no botão “enable”
Agora temos que repetir esse último passo mas desta vez para a API do Google Drive. Acesse novamente o menu ≡ → API & Services → Library e pesquise:
Selecione a API "Google Drive API”:
Aperte no botão "enable”
Gerando Credenciais de acesso.
Agora que temos tudo pronto, precisamos gerar as credencias para que a nossa aplicação possa se autenticar na nossa conta e com isso criar a manipular as planilhas.
O Google permite dois tipos de autenticação:
- User authentication: Esse tipo de autenticação irá solicitar ao usuário que autentique com sua conta google sempre que o programa for executado. É um modelo OAutho2
- App authentication: Nesse tipo de autenticação o usuário com a conta google permite que o programa se autentique em seu nome utilizando credenciais pré configuradas.
Não é escopo desse posto aprofundar no mecanismo de autenticação do Google. Se quiser se aprofundar mais, clique aqui e acesse a documentação oficial.
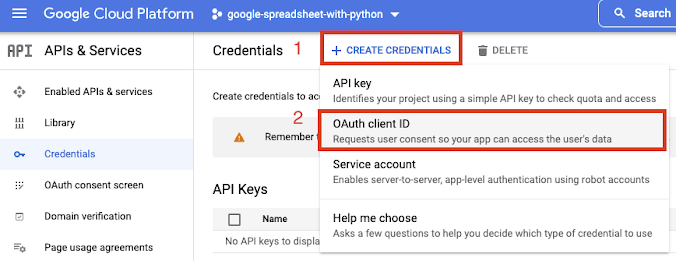
Para criar a credencial de acesso, acesse o menu ≡ → API & Services → Credentials
Na tela que abrir, aperte no botão "+ CREATE CREDENTIALS” e em seguida "OAuth Client ID”:
Na tela que abrir, aperte no botão abaixo para configurar um tela de consentimento, que será exibida para o usuário consentir que o nosso programa terá acesso a sua planilha:
Agora você tem duas opções:
- Internal: Disponível apenas para usuários do Google Workspace que é a versão para empresa das ferramentas do Google.
- External: É a opção para o público em geral.
Nesse post, vou seguir com a opção external, mas caso você possua conta no Google Workspace, pode selecionar a primeira opção.
Aperte no botão "create”.
Na tela que aparecer, preencha as informações obrigatórias e aperte "Save And Continue”
Essa é a parte mais importante, que é configurar os escopos da nossa credencial. Em outras palavras, aqui vamos definir quais permissões nosso programa irá precisar para executar seu trabalho. Essas opções serão apresentadas para o usuário dizer se permite ou não que a nossa aplicação tenha esses acessos.
Aperte no botão ADD OR REMOVE SCOPES
Você pode pesquisar ou adicionar manualmente os escopos necessários. Como a pesquisa não é muito boa, vamos fazer manualmente. Vá até a opção "Manually add Scopes" e adicione os seguintes escopos:
Quando finalizar, aperte no botão "update" e em seguida no botão "Save and continue".
O próximo passo é necessário por que o Google entende que você que o seu programa será disponibilizado para o público em geral e por tanto precisa passar pela avaliação técnica de uma equipe da Google. Isso serve para google garantir que não é um programa de fraude e nem nada do tipo.
Enquanto seu programa não é autorizado pela equipe técnica do google, você pode cadastrar alguns usuários de teste que terão acesso imediato ao programa.
Para configurar quais usuários de teste terão acesso a esse credencial aperte no botão "+ add users” e adicione o seu usuário, depois aperte no botão "save and continue”.
Agora volte na tela abaixo para finalmente criar a credencial:
Preencha os campos e aperte no botão "create":
Na próxima tela, faça download do json que contem as credenciais e guarde pois vamos utilizar no código:
Pronto, sua credencial está criado e devidamente configurado.
Uffa! vamos ao código!
Bibliotecas Python
Para o nosso exemplo, vamos utilizar 4 bibliotecas:
As 3 primeiras bibliotecas são as bibliotecas oficiais da google, com elas é possível realizar todas as operações que precisamos (copiar, criar, editar e excluir documentos), porém essas libs tem uma estrutura verbosa e difícil de utilizar, então vamos utiliza-las apenas para gerenciar nossas credencias e token.
Para realizar as operações nas planilhas, vamos utilizar uma biblioteca bem simples mas ao mesmo tempo muito completa chamada gspread. Essa biblioteca é uma interface de comunicação com a API do Google Sheets, abstraindo toda sua complexidade e verbosidade, tornando nosso desenvolvimento mais rápido e fácil. Com ela é possível realizar diversas operações como:
- abrir planilhas por título, chave e url.
- ler, escrever e formatar um conjunto de celulas
- compartilhar a planilha com outros usuários
- fazer atualizações em lote
- Diversas outras operações.
Para saber mais sobre como utilizar a biblioteca, basta clicar aqui e ler a documentação no github.
Codificando nosso exemplo
Vamos relembrar o nosso exemplo: vamos criar uma planilha no Google Drive que servirá de template e nela vamos criar duas abas: Gráficos e Ações.
A aba "Ações" servirá para carregar o nosso arquivo CSV com os dados. A aba "Gráficos" irá apresentar um gráfico de pizza com o preço das ações da primeira aba.
Nosso programa irá copiar essa template e criar uma nova planilha onde vamos fazer o upload do CSV. Dessa forma, podemos criar várias planilhas com dados e gráficos diferentes.
Passo 1 - Criar a Template
Vamos criar uma planilha em branco para servir de template. Vá até seu google drive crie um diretório, em seguida clique com o botão direito e crie uma planilha. Dê o nome de Template e crie duas abas chamadas de Gráficos e Ações.
Copie e cole (command+shift+v no MAC e ctrl+shit+v no windows) o conteúdo abaixo na célula A1 da aba Ações
ativo valor_atual min max yield valorizacao
MGLU3 6,33 5,74 26,22 0,20% -3,06%
LREN3 26,2 21,69 43,95 1,60% -1,76%
BBAS3 32,23 26,49 35,24 7,00% -0,19%
ITSA4 10,27 8,79 11,1 4,70% 1,99%
Agora na aba Gráficos, vá no menu Insert → Charts e crie um gráfico de pizza com as seguintes configurações:
Passo 2 - Autenticar e gerar o token.
Para manipular uma planilha, precisamos criar um cliente do gspread e para isso precisamos autenticar na api do google utilizando a credencial que baixamos nos passos anteriores.
import gspread
from gspread.spreadsheet import Spreadsheet
from google.auth.transport.requests import Request
from google.oauth2.credentials import Credentials
from google_auth_oauthlib.flow import InstalledAppFlow
CREDENTIALS_FILE=f'<CAMINHO PARA A CREDENCIAL BAIXADA>/credentials.json'
TOKEN_FILE=f'<CAMINHO ONDE O TOKEN SERA GERADO>/acesso/token.json'
SCOPES = [
'https://www.googleapis.com/auth/drive',
'https://www.googleapis.com/auth/drive.readonly',
'https://www.googleapis.com/auth/spreadsheets',
'https://www.googleapis.com/auth/spreadsheets.readonly'
]
def get_credentials():
credentials = None
if os.path.exists(TOKEN_FILE):
credentials = Credentials.from_authorized_user_file(TOKEN_FILE, SCOPES)
if not credentials or not credentials.valid:
if credentials and credentials.expired and credentials.refresh_token:
credentials.refresh(Request())
else:
flow = InstalledAppFlow.from_client_secrets_file(CREDENTIALS_FILE, SCOPES)
credentials = flow.run_local_server(port=0)
with open(TOKEN_FILE, 'w') as token:
token.write(credentials.to_json())
return credentials
def main():
client = gspread.authorize(get_credentials())
if __name__ == '__main__':
main()
Ao executar o código acima, um browser irá se abrir para confirmar o acesso solicitado pelos escopos. Basta confirmar e fechar o browser que o arquivo token.json será criado. Esse arquivo irá conter o token de acesso que precisamos para comunicar com a api do google. O token tem prazo de validade e precisará ser renovado quando o tempo expirar.
Passo 3 - Criar uma nova planilha a partir da template
Para realizar um cópia da template para uma planilha final, vamos primeiro verificar se essa planilha já existe e caso exista ela será removida.
TEMPLATE_FOLDER_ID = f'1WPriGQaE5cScXL8UK16FD-NCJoKUcls4'
TEMPLATE_ID = f'1b05snBcvehGex_jsN1mgtBYm7jOJZQKkuLIHJ9E4RV8'
planilha_nova = 'Versão nova'
print(f"Verificando se planilha {planilha_nova} existe")
try:
sh = client.open(planilha_nova, TEMPLATE_FOLDER_ID)
print(f"Panilha {planilha_nova} já existe e será removida")
client.del_spreadsheet(sh.id)
except:
print(f"Panilha {planilha_nova} ainda não existe")
print(f"Copiando a template para: {planilha_nova}")
client.copy(TEMPLATE_ID, title=planilha_nova, copy_permissions=True)
A variável TEMPLATE_FOLDER_ID é o identificador único do diretório que criamos e pode ser obtido direto da URL do diretório:
A variável
TEMPLATE_ID também pode ser obtida da mesma maneira:
Não se esqueça de substituir pelos valores correspondentes do diretório e planilhas que você gerou no seu google drive.
Passo 4 - Upload do CSV
Por último, vamos fazer upload do arquivo CSV para a a aba "Ações” na planilha que acabou de ser gerada
CSV_FILE = f'<CAMINHO DO CSV>/acoes.csv'
print(f"Atualizando CSV: {CSV_FILE}")
spreadsheet: Spreadsheet = client.open(planilha_nova)
with open(CSV_FILE, 'r') as file:
spreadsheet.values_update(
'Ações',
params={'valueInputOption': 'USER_ENTERED'},
body={'values': list(csv.reader(file))}
)
Passo 5 - Formatando celula (opcional)
Caso seja necessário, podemos formatar células e colunas da planilha:
print(f"Formatando Cabecalho")
aba_acoes = spreadsheet.get_worksheet(1)
aba_acoes.format('A1:F1', {
'horizontalAlignment': 'CENTER',
'textFormat': {'bold': True}
})
No nosso caso toda formatação que estiver na template será mantida na cópia mas está ai o exemplo caso seja necessário fazer alguma formatação customizada.
Dicas
Caso seu google sheets esteja configurado com o separador decimal "." você deve configurar para usar a ",”. Vá no menu File → Settings e configure o Locale para Brasil.
Conclusão
Esse foi um artigo bem extenso devido a configuração do aplicativo no google mas espero que possa ser útil para você.
O código fonte completo pode ser encontrado aqui.
Referências